

New benchmarks show that passing a medical exam is not enough. Clinical AI agents must gather information, deal with uncertainty, use tools, interpret images, and avoid bias in simulated patient encounters.
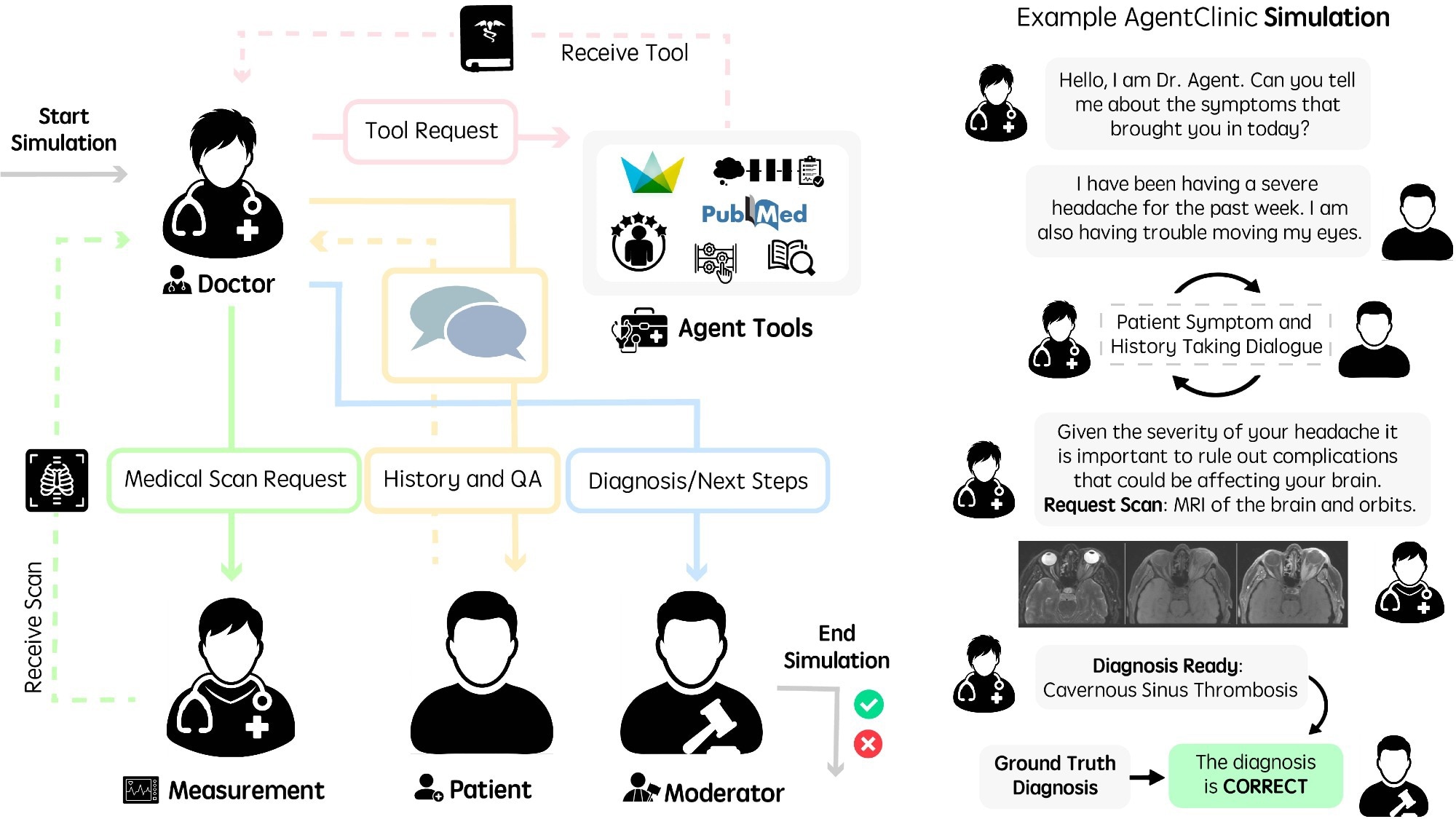
Run the language agent in AgentClinic. (Left) Agent workflow diagram for AgentClinic. The physician agent interacts with tools and agents to arrive at a diagnosis. The moderator agent compares the conclusion with the true diagnosis at the end of the simulation. (Right) Example of interaction between agents in the AgentClinic benchmark.
Recent research published in journals npj digital medicine introduced AgentClinic, a multimodal agent benchmark for clinical artificial intelligence (AI) agents in simulated clinical environments.
Building interactive systems that can solve a wide range of problems is one of the main goals of AI. Many recent large-scale language models (LLMs) have solved problems that are difficult even for humans, and have even surpassed average human scores on medical licensing exams. However, several limitations hinder its application in real-world clinical settings.
Clinical work is multiplexed and requires sequential decision-making that requires addressing uncertainty with limited resources and limited information. This feature is not reflected in the current assessment and presents all the data needed if the vignette and LLM were tasked with answering or choosing the most plausible option.
The authors noted that good performance on a static medical question answering task was only less predictive of performance in the interactive AgentClinic setting. In some cases, diagnostic accuracy dropped sharply when static cases were converted to AgentClinic’s sequential format.
AgentClinic study design and benchmark structure
In this study, researchers presented AgentClinic, a multimodal agent benchmark for LLM assessment in a simulated clinical setting. This benchmark included four language agents: a measurement agent, a physician agent, a patient agent, and a moderator. Each agent has specific instructions and provides unique information not available to other agents. A doctor agent is a model whose performance is evaluated by other agents.
We built an agent based on healthcare-related scenarios using questions from the MedQA dataset based on US Medical Licensing Exam-style cases, New England Journal of Medicine (NEJM) case challenges, and anonymized MIMIC-IV electronic medical records. The questions were about symptom-based diagnosis and were used to create a template for the prompts. For AgentClinic-MIMIC-IV and AgentClinic-MedQA, questions were selected from MIMIC-IV and MedQA datasets, respectively.
A structured input file containing case information was generated using GPT-4, and case scenarios were manually validated. In general, physician agents were given a purpose. The patient agent received the patient’s symptoms and medical history. The measurement personnel received the physical examination results. And the moderator received the correct diagnosis. The accuracy of 11 LLMs was evaluated in AgentClinic-MedQA, each acting as a physician agent and diagnosing a patient agent (GPT-4) through interaction.
Twenty interactions between the physician agent and the patient and measurement agent were allowed before making the diagnosis. Additionally, the performance of three human physicians was evaluated using the same constraints and instructions, although this small sample of clinicians should be interpreted with caution. Claude 3.5 Sonnet had the highest accuracy of 62.1%, followed by OpenBioLLM-70B (58.3%) and Doctor (54%).
AgentClinic performance across models, tools, and modalities
Furthermore, the accuracy of AgentClinic-MIMIC-IV was highest for Claude 3.5 Sonnet (42.9%), followed by GPT-4 (34%) and GPT-3.5 (27.5%). Reducing the number of interactions to 10 significantly reduces the accuracy to 25%, while increasing the number of interactions to 30 also reduces the accuracy. The accuracy of the physician agent varies depending on the patient agent. GPT-4 patient agent achieved higher accuracy than Mixtral-8x7B or GPT-3.5 patient agent.
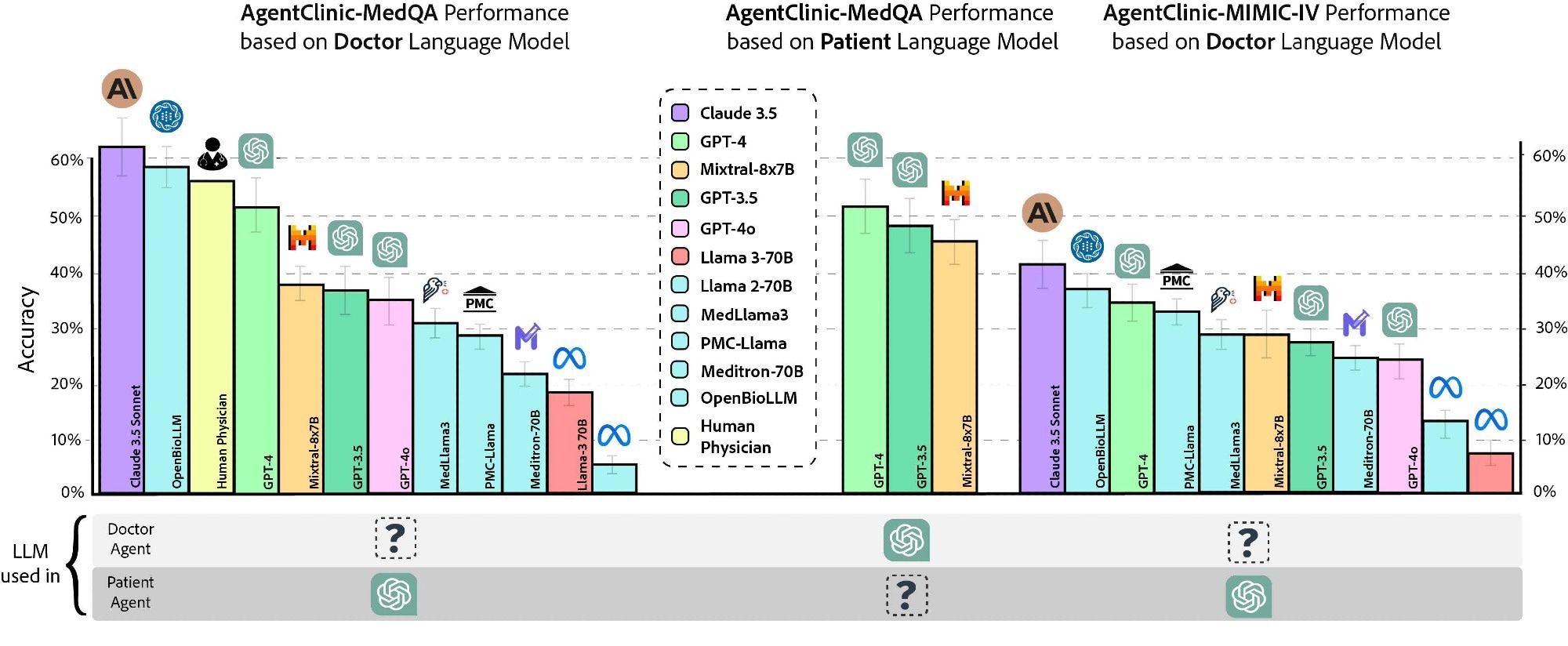
Accuracy of various physician language models and human physicians on AgentClinic-MedQA using GPT-4 patients and measurement agents (left). Accuracy of GPT-4 for AgentClinic-MedQA based on patient language model (middle). GPT-4 Accuracy of AgentClinic-MIMIC-IV by number of patients and measurement agent usage (right).
The researchers then evaluated the impact of six agent tools on diagnostic accuracy. Reflective Chain of Thought (CoT), Notebook, Zero-Shot CoT, Adaptive Search Extension Generation Using Textbook Sources, Adaptive Search Extension Generation Using Web Sources, and One-Shot CoT. Claude 3.5 Sonnet had the best performance using the Notebook tool with an average accuracy of 51.3% and a peak accuracy of 56.1%. GPT-4o and GPT-4 showed modest improvements for most tools, but tool use was not uniformly beneficial for all models.
Additionally, implicit biases (unconscious associations influenced by cultural and social norms, e.g. gender bias) and cognitive biases (systematic patterns of deviations from rationality and norms in judgments, e.g. recency bias) were included in the prompts to assess their impact on diagnostic accuracy. For GPT-4, accuracy decreased to 48% and 50.3% for patient and physician cognitive biases, and 51.3% and 50.5% for patient and physician implicit biases, respectively. The benchmark also assessed simulated patient confidence, treatment compliance, and willingness to see the same doctor again, but these ratings were derived from LLM-simulated patients rather than real patients.
The team then examined the experts’ cases using case reporting questions across nine medical specialties in the MedMCQA dataset. Consistently, Claude 3.5 Sonnet was the best-performing model, with an average diagnostic accuracy of 66.7% and superior performance in internal medicine, otolaryngology, and gynecology. Performance varies by specialty, suggesting that interaction-based diagnosis may differ from static multiple-choice medical tests. Next, the team evaluated four multimodal LLMs in diagnostic settings that require more understanding of image reading.
The researchers also evaluated multilingual cases across seven languages: English, Chinese, French, Spanish, Hindi, Farsi, and Korean. Most models performed best in English, and although there was significant variation across other languages, Claude 3.5 Sonnet maintained the strongest multilingual performance overall.
To achieve this objective, 120 questions from the NEJM Case Challenges were used. When images were first provided to the physician agent, Claude 3.5 Sonnet had a diagnostic accuracy of 37.2%, followed by GPT-4 (27.7%), GPT-4o (21.4%), and GPT-4o-mini (8%). When images were provided upon agent request, the accuracy was 35.4%, 25.4%, 19.1%, and 6.1% for Claude 3.5 Sonnet, GPT-4, GPT-4o, and GPT-4o-mini, respectively.
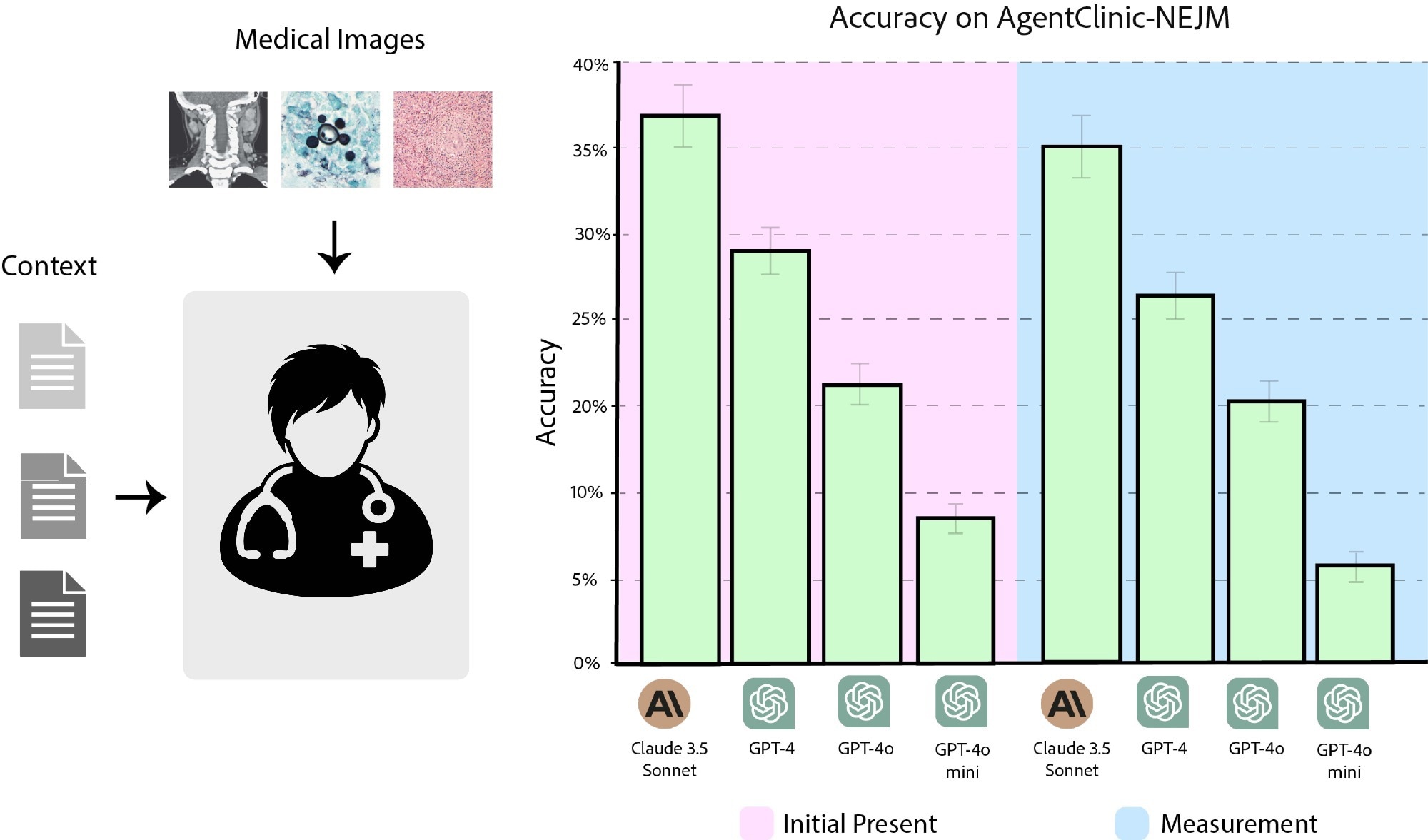
Accuracy of Claude 3.5 Sonnet, GPT-4, GPT-4o, and GPT-4o-mini on AgentClinic-NEJM with multimodal text and language input. (Pink) Accuracy when images are presented as initial input. (Blue) Accuracy when you need to request an image from an image reader.
AgentClinic’s impact on clinical AI assessment
LLMs need to be evaluated with new strategies that go beyond static question-and-answer benchmarks. AgentClinic represents a step toward building more interactive, conversation-driven benchmarks that provide a simplified clinical environment that includes agents representing moderators, patients, physicians, and measurements, and assess the sequential decision-making capabilities of LLMs across discrete, multimodal, and challenging settings. However, the authors cautioned that AgentClinic remains a simplified simulation of clinical care using LLM-based patient, measurement, and moderator agents. They also noted the potential data breach risks of their proprietary model and emphasized that the human comparison data was obtained from just three clinicians.
Therefore, these results should be interpreted as benchmark performance and not evidence that the model is ready for autonomous clinical diagnosis.
We have been grading medical AI like a multiple-choice exam. But in reality drugs don’t work that way.
A new npj Digital Medicine paper introduces AgentClinic, a benchmark in which an AI agent interviews patients, gathers missing information, and interprets multimodal. pic.twitter.com/BrS2yXJ4PL
– npj Digital Medicine (@npjDigitalMed) April 29, 2026